The Puzzling Origins of AIDS
By Jim Moore
Although no one explanation has been universally accepted, four rival theories provide some important lessons
Although no one explanation has been universally accepted, four rival theories provide some important lessons

DOI: 10.1511/2004.50.540
Shortly after the 1983 discovery of the human immunodeficiency virus (HIV), the pathogen responsible for AIDS, investigators became aware of a strangely similar immune deficiency disease afflicting Asian monkeys (macaques) held in captivity in various U.S. research labs.
Soon, virologists identified the culprit: a simian immunodeficiency virus (SIV) that is found naturally in a West African monkey species, the sooty mangabey (Cercocebus atys), but is harmless to that host. This virus, denoted SIVsm, is genetically similar to a weakly contagious form of the AIDS virus that is largely restricted to parts of West Africa, HIV-2, and thus is considered its likely precursor. More recent work has shown that the closest relative of the primary human immunodeficiency virus (HIV-1) is another simian immunodeficiency virus, one carried by chimpanzees (SIVcpz).
After comparing the SIVs in chimpanzees and sooty mangabeys with HIV-1 and HIV-2 strains, investigators concluded that there must have been multiple transmission "events" from simians to humans—at least seven for HIV-2 (some of which are known from only a single person who lives near mangabeys carrying a uniquely similar SIV) and three for HIV-1, the virus now infecting some 40 million people worldwide.

How did SIVcpz and SIVsm cross over into humans and become pathogenic? Given the lack of historical references to AIDS-like disease in Africa prior to the mid-20th century, as well as its absence previously in the New World (which imported some 10 million African slaves during the 16th through 19th centuries), that transfer appears to have happened relatively recently—exactly when is a point of considerable debate. And why did two distinct simian viruses with which humans have apparently coexisted for centuries, or even millennia, suddenly pass into humans multiple times within a few decades?
The answers to these questions have been slow in coming, despite the considerable efforts of molecular biologists to understand the nature and evolution of primate immunodeficiency viruses. I am not one of those molecular biologists; rather, I became a player in the field of AIDS-origin research through my interest in chimpanzee socioecology. Although I am partial to a theory I helped to fashion for why AIDS emerged when it did, with time it might become clear that a competing idea better accounts for genesis of the epidemic. Or perhaps the answer will prove to lie with some complex combination of factors that no single explanation presently encompasses. Whatever the case, the solution almost certainly will come from one or more of four competing theories.
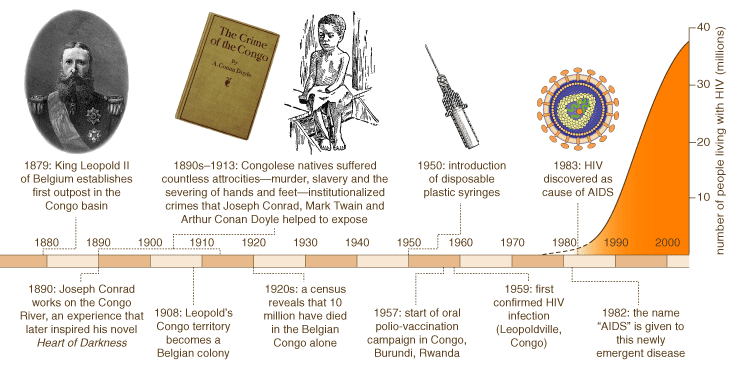
The first theory is the most controversial. In a 1992 article in the magazine Rolling Stone, journalist Tom Curtis suggested that HIV could have resulted from the use in Africa of an experimental oral polio vaccine (OPV), one contaminated by a then-unknown SIV carried most probably (Curtis supposed) by African green monkeys. Green-monkey kidney cells were widely used as a substrate to grow viruses for research and vaccine production. And one of the first major trials of an experimental oral polio virus vaccine took place from 1957 to 1960 in what are now the Democratic Republic of the Congo, Burundi and Rwanda, seemingly the "hearth" of the global AIDS epidemic. When interviewed by Curtis, Hilary Koprowski, the polio-vaccine pioneer who mounted that massive campaign, could not recall or find documentary evidence as to whether his group had used kidney cells from green monkeys or Asian macaques (which do not naturally carry an SIV). If culture media contained SIV (a possibility, given that the techniques available during that era were unable to guard against unknown viruses that did not cause overt symptoms in their monkey hosts), more than 900,000 people might have received it with their medicine, laying the basis for the current epidemic.

Photograph by Gilbert Rollais, courtesy of Edward Hooper.
Curtis credited this theory to Blaine Elswood, a Californian AIDS activist. Interestingly, the idea that the administration of a contaminated oral polio vaccine might have been involved in the genesis of AIDS was suggested independently by two others at about the same time. The first to do so was Louis Pascal, who like Elswood is not a scientist. After years of rejections, Pascal, a New Yorker, finally managed in 1991 to get the University of Wollongong in Australia to publish a paper describing his ideas. Not surprisingly, few noticed it. Attorney Walter Kyle also published a broadly similar theory in The Lancet, a British medical journal, in 1992. Since then, writer Edward Hooper, author of the controversial 1999 book The River, has become the contaminated-vaccine theory's most ardent supporter. Hooper, noting a passing mention by Curtis of a chimpanzee colony run by Koprowski's team, suggested that kidneys from these chimpanzees—not from green monkeys—may have been the original source of the virus.
Multiple localized strains of HIV have now been discovered, and mass vaccination appears unlikely to account for all of them. But the early distribution of the major pandemic strain, HIV-1 group M (for "main"), seems to fit reasonably well with the location of Koprowski's campaigns, and the OPV theory now is applied primarily to this strain.
Contamination of OPV is the only one of the four current theories that is readily falsifiable: Finding the HIV-1 group M virus in a tissue sample that predated the suspect vaccine would eliminate this possibility. So far that has not happened. Still, many investigators give the theory little weight for other reasons, which has led to the widespread belief that the theory has been definitively disproved. In 2001, for example, Science magazine published a piece titled "Disputed AIDS Theory Dies its Final Death," and Nature ran one under the heading "Polio Vaccines Exonerated." Earlier this year Nature also published "Origin of AIDS: Contaminated Polio Vaccine Theory Refuted"—a surprising title given that this theory ostensibly died three years ago.
The recent findings of various molecular biologists have indeed failed to provide support for the OPV theory. For example, in 2000 a few existing samples of the vaccine from Koprowski's home institution (the Wistar Institute in Philadelphia) were tested and found negative for both chimpanzee DNA and SIV. However, this result did not rule out the possibility, previously suggested by Hooper, that local amplification of the live-virus vaccine in Africa (to create more doses) could have introduced the SIV. The key issue is thus whether chimpanzee kidneys were used as a culture medium at any stage of Koprowski's vaccine program. There is eyewitness testimony on both sides of this question, and failure to find SIVcpz in a handful of samples of the live vaccine strain of the type used in Africa does not prove the virus was absent in (putative) locally produced batches.
A second reason to question the OPV theory also came to light in 2000, with a report in Science by Bette T. Korber (of Los Alamos National Laboratory) and colleagues. They used molecular differences among HIV-1 group M subtypes to estimate the date of their last common ancestor. The conclusion: 1931 (with 95 percent confidence limits giving the range 1915 to 1941), preceding OPV administration by decades. However, the calculation of such common-ancestor dates can be thrown off by genetic recombination among subtypes ("viral sex"), which can make such dates come out too early, and there is increasing evidence that such recombination may be common with HIV. So maybe this date is not right. On the other hand, independent analyses using different methods have supported the date, and an analogous study of HIV-2 came up with an origin for the main group between 1940 and 1945.
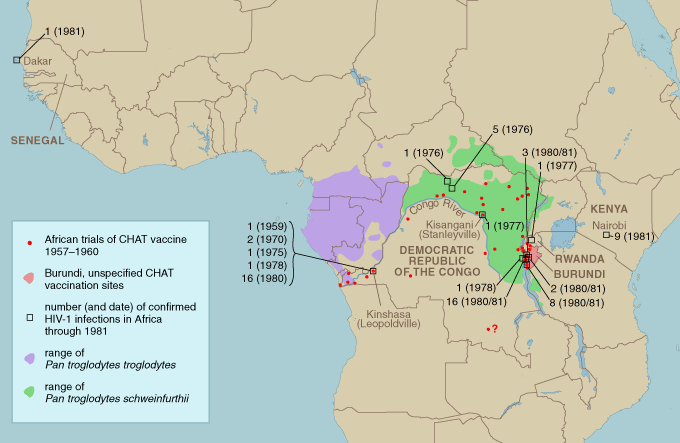
Another objection to the OPV theory concerns the subspecies of chimpanzee kept near Kisangani (formerly Stanleyville) at a facility called Camp Lindi, which Koprowski and colleagues maintain was used for safety-testing their vaccine, but which Hooper suspects was the source of chimpanzee tissues used to produce vaccine locally. The SIVcpz strain that is most similar to HIV-1 has so far only been identified in a subspecies of chimpanzee native to west-central Africa, Pan troglodytes troglodytes. A second, less similar strain has been identified only in Pan troglodytes schweinfurthii, the subspecies found in east-central Africa—where Camp Lindi was located. The nearest known populations of P. t. troglodytes are more than 500 kilometers from Koprowski's chimp colony. So, this argument goes, the locally obtained captive chimps would not have been carrying the SIVcpz strain thought to have given rise to HIV-1.
One difficulty with this argument is that distance is not always measured in kilometers, particularly in Central Africa: Kisangani lies at the upstream end of the navigable portion of the Congo River, which borders the range of P. t. troglodytes for hundreds of kilometers, and river trade has been substantial since the colonial scramble for Africa in the late 19th century. If it became known that Americans were paying good money for young apes in Kisangani, it would be almost surprising if some hunters had not made the trip upriver. Another problem is the difficulty of proving the absence of something based on only a few samples, which requires some significant assumptions about the epidemiology of SIVcpz in the wild.
In short, although the majority of the biological evidence published in the last few years suggests that the OPV hypothesis is wrong, headlines reporting the death of this theory remain premature.
The main competing theory posits that SIV is occasionally transmitted to hunters via blood-to-blood contact with an infected primate. According to this view, the virus is usually cleared in its human host, but at least several times during the 20th century it survived and became established as HIV. It is not hard to imagine hunters suffering cuts or being injured by a wounded mangabey or chimpanzee, and some form of natural transfer between species presumably accounts for the widespread distribution of SIVs in African primates. Hence, one has the "cut hunter" or "natural transfer" theory, which is probably the most accepted idea today. According to that view, the timing of the widespread emergences of HIV-1 and HIV-2 in the middle part of the 20th century is attributed to urbanization and regional commerce, which create conditions ideal for spreading a sexually transmitted disease.
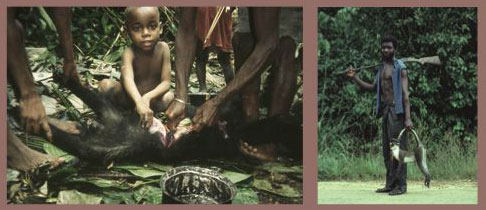
Photograph at left by Heidi Verhoef, courtesy of the Bushmeat Crisis Task Force, photograph at right courtesy of Glyn Davies, Zoological Society of London.
The next proposal, a refinement of the cut-hunter theory, comes from Preston A. Marx, a virologist who holds positions at Tulane University and at the Aaron Diamond AIDS Research Center. In 1995 he noted (to Hooper) that a big change in medical practice took place in the 1950s with the worldwide introduction of disposable plastic syringes, making guaranteed sterile use possible and dropping the cost of syringe production by almost two orders of magnitude. The result was that the medical use of injections went up astronomically. Because doses can be measured and there is no possibility of patients losing or selling the medicine, injections became a popular way for doctors in the developing world to administer medicines, including vitamins, analgesics and other common drugs.
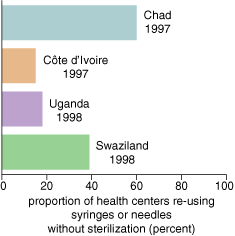
Data from Dicko et al. 2000. Illustration by Barbara Aulicino.
The problem is that trivial costs are still large to someone living outside the cash economy, and plastic syringes cannot be sterilized by boiling: they melt. According to this scenario, the widespread availability of disposable syringes increased the acceptance of injections to treat a variety of diseases, but the syringes were not so available (or cheap) as to permit users actually to dispose of them. The result was that unsterilized syringes were used again and again, spreading viruses, including those that eventually became HIV.
Marx suggests that people's immune systems would normally be able to overcome an SIV they acquired, say while butchering a monkey, within a week or two of infection. He further posits that the transition from SIV to HIV demands a series of mutations, with the probability of all the required mutations occurring being a function of viral population size. Thus, Marx contends, some way must be found to permit the SIV to remain at high levels in people for long enough that such spontaneous mutations might take place. He suggests that the required mechanism is "serial passaging" of virus through unsterile needles. That is, a cut hunter might get an injection while he is still harboring large numbers of viral particles in his bloodstream; that same needle would then be used to infect another person, who might soon receive a second injection, and so forth. High viral population levels can thus be maintained in a series of different people getting shots. With each transfer via contaminated needle, the virus finds itself in a fresh host, with an opportunity to proliferate before the infected person can mount an immune response. Chance mutations can thus accumulate, and eventually the SIV adapts, becoming HIV.
Together with two undergraduate students, I am responsible for another variant to the cut-hunter theory, so perhaps I should explain how I became engaged in this field of inquiry. In late 1998 I became involved in an e-mail discussion about the conservation implications of the identification of central African chimpanzees as the source of HIV-1, a result that Beatrice H. Hahn of the University of Alabama at Birmingham and her colleagues had just published. At about the same time, a colleague urged me to read King Leopold's Ghost, Adam Hochschild's history of the Belgian Congo, and I was independently contacted by two students, Amit Chitnis and Diana Rawls, who were interested in doing something involving the intersection of biological anthropology and medicine. Then came the catalyst: an article in Discover magazine that mentioned the idea that the origin of AIDS might have had something to do with the chaos that followed colonial withdrawal from central Africa. The notion was that the colonial authorities had kept things under control, but when they left, "there was a free-for-all" that provided the conditions for the establishment of a new disease.

King Leopold's Ghost had more impact on me than any other book I have read. I had vaguely heard that Belgian rule was harsh, but I had not realized that more Africans probably died as a result of colonial practices in French Equatorial Africa and neighboring Belgian Congo between 1880 and the onset of World War II than had been taken from Africa as slaves during the preceding 400 years. "Probably," because no record was kept of the dead. The first censuses, taken in the 1920s, estimated that the population of the two colonies was then about 15 million. Census-takers recorded that wherever they asked, local people (colonial and native) reported that about twice as many had lived there two or three decades before, indicating that some 15 million had died. Losing 50 percent of the population exceeds even the 35-percent fatality rate of the Black Death in Europe.
It seems Joseph Conrad's Heart of Darkness was as much fact as fiction, and the horror described in that famous novel reflected official policies in the Congo as much as individual insanity. What appeared to many as colonial "control" of the region in the late 19th and early 20th centuries brought chaos to the lives of the Africans who lived and died under it. Chitnis, Rawls and I set out to see what disease-promoting factors might have existed prior to the withdrawal of colonial powers around 1960.
Data on rise in HIV infections from UNAIDS. Illustration by Barbara Aulicino.
Candidates were not difficult to find, at least during the years prior to World War I. Forced labor camps of thousands had poor sanitation, poor diet and exhausting labor demands. It is hard to imagine better conditions for the establishment of an immune-deficiency disease. Where imagination fails, let history serve. To care for the health of the laborers, well-meaning but undersupplied doctors routinely inoculated workers against smallpox and dysentery, and they treated sleeping sickness with serial injections. The problem is, the multiple injections given to arriving gangs of tens or hundreds were administered with only a handful of syringes. The importance of sterile technique was known but not regularly practiced: Transfer of pathogens would have been inevitable. And to appease the laborers, in some of the camps sex workers were officially encouraged.
And that was just the situation in the camps. Major efforts were made to eradicate smallpox and sleeping sickness elsewhere in the region (these diseases cut into productivity). The shortage of syringes was acute. One 1916 sleeping-sickness control expedition treated 89,000 people in Ubangi Shari (now Central African Republic) using just six syringes. And before the introduction of dried smallpox vaccine in about 1914, the only way to transport vaccine to the interior was by serially inoculating people, traveling during the eight-day interval required for the new carrier to develop pustules from which the next inoculation could be derived. There are records of at least 14,000 people receiving vaccine in this way. The method had been abandoned in Europe some 20 years before, because syphilis was all-too-often transmitted accidentally in the process.
Such circumstances easily could have promoted the evolution of HIV from SIVcpz. Imagine, for example, the following scenario:
A fisherman flees his small village to escape a colonial patrol demanding its rubber quota; as he runs, he grabs one of the unfamiliar shotguns recently arrived in the area. While hiding for several days, he shoots a chimpanzee and, unfamiliar with the process of butchering it, is infected with SIVcpz. On return to the village he finds his family massacred and the village disbanded. He wanders for miles, dodging patrols, until arriving at a distant village. The next day he is seized by a railroad press gang and marched for days to the labor site, where he (along with several hundred others) receives several injections for reasons he does not understand. During his months working on the railroad, he has little to eat and is continually stressed, susceptible to any infection. He finds some solace in one of the camp prostitutes (themselves imported by those in charge), but eventually dies of an undiagnosed wasting—the fate of hundreds in that camp alone. Disease, starvation, abuse—no record is kept, none of the authorities knows, and those few doctors who care are overwhelmed.
We wrote up a short article laying out reasons to at least examine colonial-era practices seriously in regard to how they may have contributed to the origin and spread of HIV. It probably would have been ignored but for another coincidence: Our paper appeared in the journal AIDS Research and Human Retroviruses almost simultaneously with the report of Korber and her colleagues in Science placing the beginnings of HIV-1 Group M in the early decades of the 20th century. If this dating is correct, the colonial-policy theory offers an explanation. Note, however, that a version of the basic cut-hunter theory that does not rely on urbanization (or sets a much lower threshold for the critical level of city life) could also explain the genesis and initial spread of HIV during this period.

Neither of these scenarios neatly accounts for the decades between the postulated origin of HIV in the early part of the 20th century and the widespread emergence of AIDS in Africa, which did not take place until the early 1980s. But maybe that long delay is only an artifact of our perceptions: Starting with a single case and assuming a doubling in frequency every few years, one would need decades to pass for the prevalence to build appreciably; would colonial doctors have noticed an initially rare immune disease? Nor do these theories readily explain details of the spatial pattern in the early cases of HIV infection and AIDS, which indeed show a suggestive overlap with the sites of oral polio vaccination. But is that correspondence just a function of the distribution of population and doctors? As with all of the current ideas, one can suggest various explanations to account for intriguing observations or troubling discrepancies. For the moment, the fit between theory and observation remains loose enough that no one view has proved absolutely compelling.
Arguments over rival theories of the origin of AIDS have raged viciously at times—far beyond the norms of most scientific debates. Indeed, both sides in the OPV controversy have in the recent scientific literature gone so far as to accuse their opponents of lying and manipulating evidence. I only became aware of the explosive nature of the debate after my students and I unwittingly wandered into this minefield.
Some of the participants in this controversy appear unwilling even to entertain the possibility of being wrong. Given the precarious status of each of the current theories, it seems more reasonable to try to keep an open mind until better evidence emerges and, in the meantime, to consider the literature on each of these origin stories as representing a highly refined simulation scenario. Insofar as there is any material benefit to come from understanding the origin of HIV in terms of cautionary tales, each model can and should be considered plausible—and worrisome. After all, unsterile needles do transmit diseases, contaminated polio vaccine did spread a simian virus (one called SV40) to millions of people, doctors do sometimes conduct risky research, colonial policies did have major health consequences, and contact with wild animals can introduce pathogens into humans.
An obvious general lesson can be drawn from all four theories: For some very puzzling reason, the origin of HIV was not fundamentally natural, given that humans apparently failed to acquire an immunodeficiency virus from simians during thousands of years of exposure. Instead, the emergence of HIV involved social change in one form or another: the abuses carried out at the hand of an invading foreign power; abrupt urbanization overwhelming the ability of medical and political authorities to manage the process; the undersupervised transfer of medical technology and half-measures in development programs; doctors taking liberties in distributing medicines without adequate precautions. It is worth noting that three of the four theories postulate an origin for AIDS that involves the inadvertent results of medical efforts, with what were then state-of-the-art health programs and technologies carrying with them unforeseen dangers.
Whether understanding the origin of HIV and AIDS is useful for evaluating risks associated with present-day concerns (say, the consumption of wildlife that might be the natural reservoir for emerging diseases like SARS, or evaluating the likelihood that the transplantation of animal organs into people will unleash a dangerous new virus) is a matter of opinion. My own view is that a firmer grasp of what happened in the past—and what might easily have happened had circumstances been slightly different—helps society to understand these dangers and to minimize the risk of sparking the next global scourge.
Click "American Scientist" to access home page
American Scientist Comments and Discussion
To discuss our articles or comment on them, please share them and tag American Scientist on social media platforms. Here are links to our profiles on Twitter, Facebook, and LinkedIn.
If we re-share your post, we will moderate comments/discussion following our comments policy.