Common claims that management of animal populations in the United States and Canada is “the best in the world” and “science-based” are often unfounded. But substantial improvements are possible.
In August of 2016, on an uncharacteristically sunny day scented by sea breeze, wood smoke, and summer vegetation, two dozen people were gathered for a funeral.
Members and close collaborators of the Haíɫzaqv, Kitasoo/Xai’xais, Nuxalk, and Wuikinuxv First Nations were in Kwatna, a sprawling estuary on the British Columbia Central Coast at the interface between the “Great Bear” temperate rain forest and the sea.
Three years earlier, a young grizzly bear had been killed within sight of a sign declaring that laws of the area’s four First Nations forbade grizzly hunting throughout the region. When a prominent hunter shot this bear, he was in contravention not only of these millennia-old laws, but also of additional provincial laws on residency requirements. Three years later, following a lengthy court battle and a guilty verdict, the bear’s remains had been brought home for good.
The purpose of the 2016 gathering was to take care of not only the bear that had been shot, but also those bears that remain and those yet to be born. For the four First Nations whose territories comprise what is now called the Central Coast of British Columbia, grizzly bears are not just a species of great ecological importance; they are considered close relatives. And befitting that close connection, grizzly bears are the subject of considerable stewardship activities—with efforts going well beyond forbidding trophy hunts to include on-the-ground yearly monitoring of population dynamics, land-use planning geared toward protecting key grizzly bear habitat, and working to understand and protect important foods such as salmon, which are essential for sustaining the people and ecosystems of the region.
Indigenous-led stewardship of all species, including those that are hunted for food, and of the places they inhabit provides in some ways a best-case example of what wildlife management can be: inspired by a close relationship to wildlife and their habitats, informed by knowledge and values borne of the deep history of that relationship, complemented by cutting-edge science, and led by people who not only live in the area but also shoulder the consequences of management directly—well aware that their decisions will determine the world that their children and their children’s children will inherit. However, wildlife management as it is currently practiced across most of Canada and the United States takes a very different approach.
Howard Humchitt (right) pours nonreward lure (bait that cannot be consumed by the target species) as he sets up a noninvasive bear-monitoring site in Haíɫzaqv territory in British Columbia, Canada. On the left, Harvey Brown collects a fur sample from another site in this territory. Humchitt and Brown do research as part of a monitoring partnership among the Raincoast Conservation Foundation, the Central Coast Bear Working Group, and university collaborators. Indigenous-led stewardship of grizzly bears in the region now known as the Great Bear Rainforest demonstrates how wildlife management can reflect a broad set of conservation values.
Photograph by April Bencze/Raincoast Conservation Foundation (right); Chris Darimont (left)
Ad Right
Recent rollbacks of environmental protections in the United States might give the impression that impaired relationships with the environment are a new development, a symptom of current politics. It might be true that environmental threats are increasing—in some cases, seemingly intentionally. But with regard to policy in Canada and the United States, cracks in the veneer of wildlife management as science-based stewardship and conservation run far deeper than ephemeral political cycles. However, substantial improvements are possible. If agencies can find the will to improve, there are ample ways to do so.
Wildlife Management History
The current practice of wildlife management in Canada and the United States has its roots in the early 1900s. Following a period of excessive hunting that infamously wiped out previously foundational species such as bison and passenger pigeons from wide swaths of the map and that substantially shrank the ranges of other species, there was a shift toward a “wise use” approach to managing wildlife. This philosophy, based on maximizing the number of animals that humans could extract each year, followed from the European model of scientific forestry, which treated forests as crops, tended and managed to obtain maximum yields over time.
If a given wildlife population was actually considerably smaller than the people managing it had assumed, then an ostensibly sustainable kill rate might in fact not be sustainable at all.
The author and conservationist Aldo Leopold, often seen as the father of modern wildlife management, was himself a trained professional forester and applied this philosophy to the new field of wildlife management. To address the wildlife population collapses of this time period, unregulated access to wildlife was replaced with a system that treated wild animals as optimizable resources, with extraction rates controlled and administered by central agencies. A professional society was developed, wildlife agencies adopted the model, and universities began training wildlife managers in the emerging field.
Many decades later, the main thrust of this approach remains in effect. It is now formally described as the North American Model of Wildlife Conservation. This model describes how management is conducted across Canada and the United States, and has been adopted by management agencies across provinces, territories, and states. It is based on the following seven tenets: Wildlife is a public trust; should not be subject to market forces; should be “allocated” (to hunters) by law; can only be killed for “legitimate” purposes; and must be considered an international resource (because of migrating species, for example). Science should be the basis of decision-making about wildlife policy; and hunting should be “democratic” (meaning available to everyone).
At a gathering to put to rest a grizzly bear’s remains after it had been illegally killed as a trophy, members of the Haíɫzaqv, Kitasoo/Xai’xais, Nuxalk, and Wuikinuxv First Nations and their close collaborators stand in front of a new sign declaring the end of trophy hunting on tribal lands in Kwatna, a large estuary in British Columbia. The bear was killed near this location, in view of another sign banning trophy hunting.
Photo courtesy of the author.
An overview of the model reveals something that might come as a surprise to much of the public: Wildlife management in Canada and the United States primarily means management of hunting, and it is focused on the small subset of the human population that hunts, not on the conservation of species and their habitats for their own sake. Some of the blurring is likely intentional, an adaptation of organizations to evolving cultural mores that place a high value on conservation. For example, the Boone and Crocket Club, the world’s first hunting club, describes itself as a pioneer in conservation, and adheres to the aforementioned wildlife model that guides hunting across Canada and the United States, the North American Model of Wildlife Conservation. However, even though conservation and wildlife management might overlap, understanding where they don’t can be critical, especially as it pertains to management ostensibly done on behalf of the public.
Conservation is certainly not incompatible with hunting. Cultures across North America were sustained by animal populations for millennia before European colonization triggered the widespread degradations seen in recent centuries. However, the two can certainly be at odds.
The western United States is a region that epitomizes the tension between hunting and conservation. Yellowstone National Park has gained permanent tenure in ecological textbooks by undergoing what many have described as an ecological rebirth, kicked off by the reintroduction of wolves and their keystone ecological functions. From a conservation perspective, the return of wolves is great. But tell that to the folks behind antiwolf billboards that pepper state roads leading to the home of this conservation success story.
The prowolf and antiwolf sentiments here confront a central fact: Wolves are predators. Whether that’s a good or a bad thing depends on whom you ask. It’s certainly much easier to hunt elk when they exist at high densities—for example, after a population has been released from predation pressure. Whether these high densities are worth the ecological degradation of overgrazing depends on whether priority is given to maximal human hunting opportunities or to ecological integrity. Similarly, whether the potential ecological benefits of wolf populations are worth the threat (real or perceived) of occasional livestock predation depends on whether priority is given to protection of economic activities or to protection of ecological integrity. Although many people might assume that wildlife management would lean toward prioritizing conservation rather than exploitation, much evidence suggests otherwise, including the very tenets of the North American Model of Wildlife Conservation.
What Does “Science-Based” Mean?
Grizzly bear ecology and conservation in British Columbia, Canada, provide a window into the world of North American wildlife management. In 2010, I worked with colleagues from Simon Fraser University, the University of Victoria, and the Raincoast Conservation Foundation to begin investigating the science behind the socially maligned and culturally opposed trophy hunting of grizzly bears, a hunt that politicians have frequently defended, claiming that their support for the practice has a scientific basis. We began with a straightforward analysis, comparing the number of bears hunted in populations across the province with the number of kills that government biologists had deemed sustainable. We found that these mortality limits were exceeded in half of the provincial populations.
In the United States and Canada, wild animals such as grizzly bears (left), gray wolves (middle), and bighorn sheep (right) are managed under the North American Model of Conservation, which emphasizes hunt management rather than the conservation of species and their habitats for their own sake.
Left two photos courtesy of the author; right photo courtesy of Paul Paquet.
During this analysis, we learned that there was considerable uncertainty about key attributes (population sizes, growth rates, and poaching rates) that had been used to determine mortality limits. This uncertainty was largely ignored in hunt allocations, an oversight that had important ramifications. For example, if a given managed population was considerably smaller than the people managing it had assumed, an ostensibly sustainable kill rate might in fact not be sustainable at all. We wondered how this unaddressed uncertainty might be affecting these managed populations. Our quantitative investigations found the effect might have been substantial, with a risk of accidental overkills in up to 70 percent of the periods and populations we examined. We also found that overkills would have been undetectable in most of these cases because of data deficiencies.
Insight from fisheries management science provided guidance on how these risks could be addressed. Using approaches taken more commonly by those investigating the sea but relatively rarely by landlubbers, we illustrated how quotas could be set that buffer against uncertainty. Reducing quotas, using a straightforward, transparent approach, could lessen risks of overkill.
The British Columbian government response the month after our publication was surprising. They announced an increase in hunt quotas and a reopening of previously closed areas. In other words, the risks we had previously identified had not been reduced; rather, they had been amplified—even though the government was repeating the refrain that they were taking a cautious, science-based approach to management. The province-wide hunt was ultimately banned in 2017 after a change in government, with the decision largely ascribed to societal considerations (polling data suggested that more than 90 percent of the population of British Columbia was opposed to the trophy hunting of bears). Controversy remained to the end, with some provincial biologists arguing for the ultimate sustainability of this hunt. Regardless of the actual numerical effect of hunting across British Columbia’s grizzly bear population (this effect remains unknown, given insufficient data), the agency seemed unwilling to consider scientific evidence that ran contrary to the status quo.
Conservationist and author Aldo Leopold, often seen as the father of modern wildlife management, is shown here hunting birds with his dog Gus in October 1943. Leopold applied forestry methods to wildlife management, treating animals as optimizable resources. His work is often seen as having been a critical step forward in addressing the environmental issues of his day, but whether his approach is sufficient in addressing current issues is debatable. Although Leopold’s thinking later evolved toward a broader “land ethic” that was much more akin to conservation for its own sake, the treatment of wildlife as an optimizable resource has remained a mainstay of contemporary wildlife management.
The Aldo Leopold Archives/The University of Wisconsin-Madison Archives
The seeming incongruence between science and so-called “science-based management” led us to wonder whether this situation was an anomaly. We knew of parallels—for example, wolf culls in the United States and badger culls in the United Kingdom had been conducted with questionable scientific justifications—but were these just a few “bad apples”? Was wildlife management otherwise rigorous? After we published a letter in Science titled “When science-based management isn’t,” we learned of additional cases in which management wasn’t as evidence-based as some people claimed, leading us to test how widespread this problem might be.
We began a multiyear collaboration to investigate wildlife management across 62 U.S. states and Canadian provinces and territories, seeking empirical insight into the extent to which the management process approximates what might be considered “science-based.” Although claims of a scientific basis are common across both countries, what a scientific basis actually means is rarely defined.
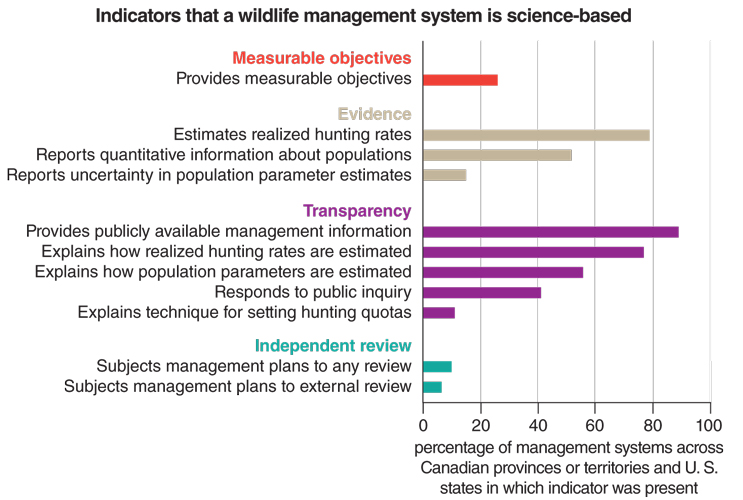
To address this confusion, we scoured the literature on science and management, and identified four foundational hallmarks of a scientific basis: clear objectives, evidence, transparency, and external review. We then looked for these hallmarks across 667 systems (for example, moose management in Alaska and mule deer management in Alberta), using all relevant publicly available documents and a set of “indicator criteria” for each hallmark (for example, an explanation of the technique for setting hunting quotas was used as an indicator for the transparency hallmark). After initial assessments, we emailed 624 agencies—all of those for which contact information was available (94 percent of the total number of agencies studied), providing agency representatives the opportunity to correct any errors we might have made in scoring, and to share with us any publicly available documents that we might have missed.
Despite the common claim that wildlife management is based in science, standards for good science (measurable objectives, evidence, transparency, and independent review) were met in only a minority of 667 wildlife management systems in U.S. states and Canadian provinces or territories.
Figure adapted from Artelle, et al. 2018a.
Our results revealed surprising patterns: In most of the systems investigated (60 percent), we found fewer than half the indicator criteria present. There were some particularly striking omissions. For example, only 26 percent of systems provided measurable objectives, 9 percent explained the technique for setting quotas, and less than 10 percent indicated that their plans underwent any form of review (even internal review).
The shortcomings we identified are not trivial. Although activities such as hunting and trapping might conjure visions of bucolic vistas touched only lightly by outdoor enthusiasts, in reality they represent an enormous extractive industry on a continental scale. As a 2015 Science publication by Chris Darimont and his colleagues at the University of Victoria and the Raincoast Conservation Foundation has shown, in many animal populations, more adults are killed by people than by all other predators combined. Thus, misguided management has the potential for large-scale consequences.
The effects of managed exploitation might extend far beyond targeted species. The environmental journalist Ben Goldfarb has recently published a book on the ecological importance of beavers, titled Eager: The Surprising, Secret Lives of Beavers and Why They Matter. By phone from Spokane, on the heels of one of the worst wildfire seasons in history, he waxed ecologically about the myriad benefits his buck-toothed protagonists provide. They serve as keystone engineers of ecosystems across the continent, creating firebreaks that help to attenuate large-scale wildfires, providing habitat for endangered salmonids, supporting sedges eaten by one of the rarest butterflies in North America, and improving water quality by entrapping sediments, filtering agricultural runoff, and raising water tables.
Beavers also serve as textbook examples of the conflict between conservation and wildlife management objectives. The book contains slapstick scenarios of various government-led initiatives operating in direct contradiction to one another. During our phone call, Goldfarb said incredulously, “In Wyoming’s Bridger-Teton National Forest, you have the Forest Service working to reintroduce beavers into watersheds as a restoration tool. At the same time, you have the state permitting trapping of those very same beavers. There are cases of folks carefully planning and carrying out the restoration of beavers to a particular stream, only to have the phone ring with a trapper calling to say, ‘Hey, I’ve just bagged one of your ear-tagged animals!’”
Beaver relocations, like the one shown above that was carried out by the Methow Beaver Project in Washington, seek to reintroduce the animals into watersheds where their effects will help their ecosystem. Policies about beavers offer an example of the conflict between conservation and wildlife management objectives. In Wyoming, the U.S. Forest Service is reintroducing beavers into watersheds in the Bridger-Teton National Forest, while the state permits trapping of the same beavers.
Ben Goldfarb
Goldfarb explained how this story illustrates the contradiction between beavers viewed through a lens of conservation and beavers viewed through a lens of human interests. He also noted similar contradictions elsewhere across the country. For example, thousands of beavers are killed to address complaints such as blocked culverts and property flooding. Effective, nonlethal alternatives are used far less frequently.
Is Policy Due for a Change?
Our criticism of the current approach to North American wildlife management has met with pushback, including from some of the most prominent proponents of the North American Model. Defenders of the current model have variously suggested that the “hallmarks of science” framework that we provided is incomplete or does not adequately describe science-based management; that some management systems not covered by this analysis (such as systems for managing migratory waterfowl, which were excluded because they are subject to additional federal and international legislation) might have a greater scientific foundation than the state and provincial management we examined; and that regardless of the results uncovered, it is not fair to focus on Canadian and U.S. jurisdictions, because these represent the “best management in the world.” (No supportive evidence is offered for this claim, a phenomenon we described in a formal reply as “fact by assertion.”)
Taken as a whole, the pushback has been helpful for moving this important discussion forward. In particular, these exchanges have suggested how future research could advance the understanding of wildlife management at a continental scale. Without a common definition of what is actually expected of science-based management, and without an agreed-upon standard to which those who invoke the term science in defense of preferred policies can be held, critics and proponents of the current model risk simply talking over one another instead of constructively working toward addressing shortcomings. The hallmarks of science we described provide clarification, but future work could expand and build upon them.
In many animal populations, more adults are killed by people than by all other predators combined. Thus, misguided wildlife management has the potential for large-scale consequences.
There are some positive examples of progress in wildlife management in both countries. For example, in the United States some state agencies increasingly recognize the ecological importance of beavers. This is especially the case in agencies also tasked with protecting species recognized to be beaver beneficiaries (such as salmonids in western states).
In Canada, the recent ban on grizzly bear trophy hunting in British Columbia serves as an example of nonconsumptive considerations (such as the ecological, cultural, social, and inherent value of a species) seeming to outweigh the consumptive interests held by a decidedly small portion of the population, which nevertheless often holds sway over wildlife management direction and decisions. In this case it was very clear where the science began and ended. Although unaddressed concerns about hunt sustainability remain, politicians transparently disclosed the true reasons for the hunt closure instead of invoking science as a catchall justification for preferred policy. We were also enthused to receive positive feedback from both conservationists and practitioners who are using our framework to inform ongoing management evolution in their particular jurisdictions. Finally, although their contribution is often overstated, hunters and trappers do make direct contributions to conservation and other ecological considerations, especially in the realm of habitat conservation.
Almost a century has passed since Aldo Leopold’s era and the birth of North America’s current approach to wildlife management, which is based on regulating hunting and maximizing “harvests” of wildlife. Although this development might have been a critical step forward in addressing the issues of the day, whether the current approach is sufficient to address contemporary environmental issues is less certain. Debates about how to tweak the model—such as changing quotas or closing certain areas to exploitation—are common. But perhaps what is needed is a deeper assessment of the very foundation of management as we know it. Insight and governance from a broader suite of people than is currently the norm might prove critical.
In British Columbia, restoring a focus on ecotourism and First Nations’ governance of wildlife has resulted in an approach that is more conservation-oriented than the region’s previous wildlife management strategy.
The 2016 meeting of stewardship practitioners in Kwatna provided insight into another way of interacting with wildlife, one that has existed in many places in North America for millennia. In rethinking the current continental status quo approaches to management, in some cases the most appropriate change might be brought about by supporting the resurgence of indigenous governance of wildlife.
The conservation of bears and other wildlife in the region now known as the Great Bear Rainforest provides a strong example of how successful support for indigenous stewardship can be; there is considerable potential to expand this approach in the future. Elsewhere, change might come from rethinking the guiding principles of the North American Model to address the gaps in scientific foundations and the misalignment with a more conservation-oriented approach.
No matter what direction that evolution takes, good governance demands transparency and an honest discussion about where the science begins and ends. Ultimately, management is paid for by—and ostensibly conducted on behalf of—the public; approaches that reflect that might go a long way toward ensuring healthy environments for generations to come. There are strong opportunities for improving the stewardship of biodiversity at a continental scale. It remains to be seen whether agencies have the political will to enact them.
In this article, Kyle A. Artelle writes on behalf of five research collaborators: John D. Reynolds and Jessica C. Walsh of Simon Fraser University; Adrian Treves of the University of Wisconsin, Madison; and Paul C. Paquet and Chris T. Darimont of Raincoast Conservation Foundation and the University of Victoria.
Bibliography
Artelle, K. A., S. C. Anderson, A. B. Cooper, P. C. Paquet, J. D. Reynolds, and C. T. Darimont. 2013. Confronting uncertainty in wildlife management: Performance of grizzly bear management. PLoS ONE 8(11):e78041.
Artelle, K. A., J. D. Reynolds, A. Treves, J. C. Walsh, P. C. Paquet, and C. T. Darimont. 2018a. Hallmarks of science missing from North American wildlife management. Science Advances 4(3):eaao0167.
Artelle, K. A., J. D. Reynolds, A. Treves, J. C. Walsh, P. C. Paquet, and C. T. Darimont. 2018b. Distinguishing science from “fact by assertion” in natural resource management. Response to eLetter. Science Advances 4(3):eaao0167. http://advances.sciencemag .org/content/4/3/eaao0167/tab-e-letters.
Artelle, K. A., J. D. Reynolds, A. Treves, J. C. Walsh, P. C. Paquet, and C. T. Darimont. 2018c. Working constructively toward an improved North American approach to wildlife management. Science Advances 4(10):eaav2571.
Artelle, K. A., et al. 2018d. Values-led management: The guidance of place-based values in environmental relationships of the past, present, and future. Ecology and Society 23(3):35.
Clark, S. G., and C. Milloy. 2014. The North American Model of Wildlife Conservation: An analysis of challenges and adaptive options. In Large Carnivore Conservation eds. S. G. Clark and M. B. Rutherford, pp. 289–324. Chicago, IL: University of Chicago Press.
Darimont, C. T., C. H. Fox, H. M. Bryan, and T. E. Reimchen. 2015. The unique ecology of human predators. Science 349(6250):858–860.
Darimont, C. T., P. C. Paquet, A. Treves, K. A. Artelle, and G. Chapron. 2018. Political populations of large carnivores. Conservation Biology 32:747–749.
Eichler, L., and D. Baumeister. 2018. Hunting for justice: An Indigenous critique of the North American Model of Wildlife Conservation. Environment and Society 9(1):75–90.
Godfray, H. C. J., et al. 2013. A restatement of the natural science evidence base relevant to the control of bovine tuberculosis in Great Britain. Proceedings of the Royal Society B: Biological Sciences 280(1768):20131634.
Housty, J. 2016. Rematriating Cheeky’s remains. Coastal First Nations website, posted September 1, 2016. https://coastalfirstnations .ca/rematriating-cheekys-remains.
Mawdsley, J. R., et al. 2018. Artelle et al. (2018) miss the science underlying North American wildlife management. Science Advances 4(10):eaat8281.
Morell, V. 2014. Science behind plan to ease wolf protection is flawed, panel says. Science 343(6172):719.
Serfass, T. L., R. P. Brooks, and J. T. Bruskotter. 2018. North American Model of Wildlife Conservation: Empowerment and exclusivity hinder advances in wildlife conservation. Canadian Wildlife Biology and Management 7(2):101–118.
Treves, A., K. A. Artelle, and P. C. Paquet. 2018. Differentiating between regulation and hunting as conservation interventions. Conservation Biology. Published online doi: 10.1111/cobi.13211.
American Scientist Comments and Discussion
To discuss our articles or comment on them, please share them and tag American Scientist on social media platforms. Here are links to our profiles on Twitter, Facebook, and LinkedIn.
If we re-share your post, we will moderate comments/discussion following our comments policy.








American Scientist Comments and Discussion
To discuss our articles or comment on them, please share them and tag American Scientist on social media platforms. Here are links to our profiles on Twitter, Facebook, and LinkedIn.
If we re-share your post, we will moderate comments/discussion following our comments policy.