Imaging Without Lenses
By David Stork, Aydogan Ozcan, Patrick R. Gill
New imaging systems, microscopes, and sensors rely on computation, rather than traditional lenses, to produce a digital image.
New imaging systems, microscopes, and sensors rely on computation, rather than traditional lenses, to produce a digital image.

Ever since medieval artisans first learned to grind glass lenses and curved mirrors that could project optical images, such devices have been used to make microscopes, camera obscuras, telescopes, and other instruments that enable us to better see objects both small and large, near and distant, on Earth and in space. The next revolution in imaging came near the middle of the 19th century with the invention of photography, which made it possible for optical images to be fixed permanently, reproduced, and printed widely. That era of chemical photography is coming to an end, having been increasingly eclipsed in the third revolution—digital imaging—which has its roots in the technology of television, but can best be dated to the 1975 invention of the digital camera. Today billions of webcams and digital still and video cameras on mobile phones worldwide capture more than a trillion images per year, many of which are shared instantly on the internet. Throughout this remarkable expansion in the number, variety, and uses of imaging systems, the task of optical designers has remained for the most part unchanged: to make a high-quality optical image that mimics the scene as faithfully as possible—one that “looks good.”
In the past decade or two, however, a new paradigm, the fourth revolution in imaging, has emerged: computational imaging. Although this paradigm may not completely supplant traditional approaches, it questions centuries-old assumptions and provides alternative methods for designing imaging systems. It has led to novel imaging functions and forms, including ultraminiature imagers for recording macroscale objects, and microscopes that eschew lenses altogether.
As its name suggests, the key advance in this new paradigm is the essential role played by computation in the formation of the final digital image. Digital image processing has long been used to improve images, of course—such as eliminating “red eye” in flash portraits or balancing the color to correct for a red sky at sunset—but the design of the optics had never been influenced by such needs. Digital signal processing can go further and correct some optical defects, however. When the orbiting Hubble Space Telescope first sent its photos to Earth in the late 1980s, the images were far blurrier than expected; it quickly became apparent that something was wrong with the telescope optics. NASA scientists diagnosed the optical problems and, in the years before the unmanned telescope could be repaired, designed sophisticated digital processing algorithms to correct the images by compensating for many of the effects of flawed optics.
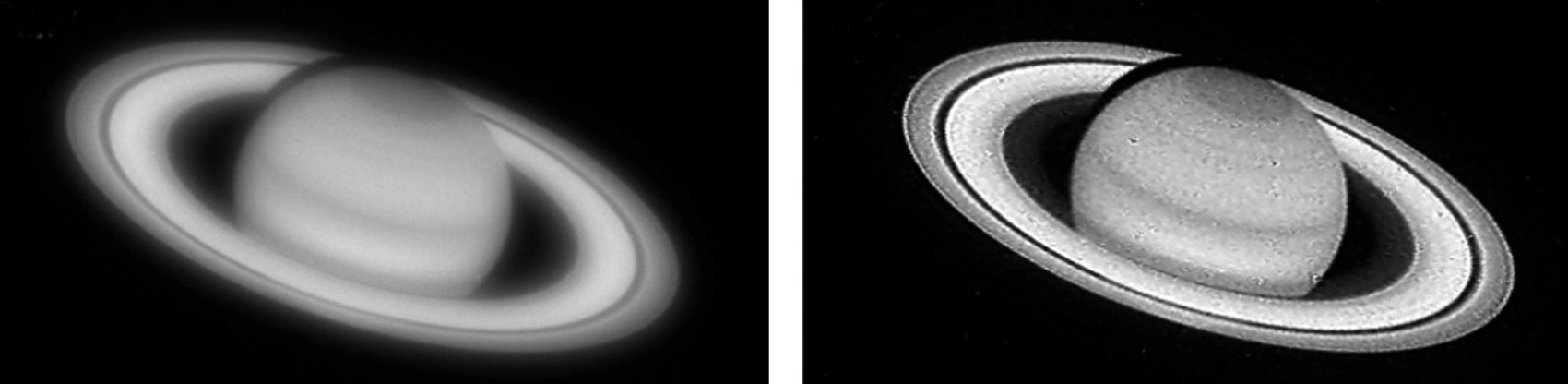
Images courtesy of Richard R. White.
In the mid-1990s, W. Thomas Cathey and Edward R. Dowski, Jr., realized that one could go further still: One could intentionally design optics to produce blurry, “degraded” optical images, but degraded in such a way that special digital processing would produce a final digital image as good as, or even better than, those captured using traditional optics. Specifically, they addressed a property of all traditional cameras: limited depth of field. If you focus your camera on an object at an intermediate distance, its image appears sharp, but the images of objects closer or farther away appear blurry. The range of distances at which an image is acceptably sharp is called the camera’s depth of field. These scientists designed a new kind of lens element that blurred the optical images of objects at every distance in nearly the same way. Then, a special image-processing algorithm sharpened the entire image, thereby effectively extending the depth of field beyond what was possible using a traditional camera. Although a number of groups—including one led by one of us (Stork)—have extended this pioneering work, Cathey and Dowski’s deep insight has propelled the field of computational sensing and imaging in ways few could have anticipated.
Another way to understand their insight is to realize that the task of optics is now to make optical images for a computer—not for a human. Paradoxically, in this era seemingly swamped with images, few humans directly see true optical images generated by imaging systems such as cameras anymore: Long gone are the days when a photographer, head under a black cloth, looked at an optical image on a view camera’s ground-glass screen before inserting the plate of film. Instead, we now look at the contents of processed digital files as displayed on computer, tablet, or mobile phone screens.
In this era seemingly swamped with images, few humans directly see true optical images generated by imaging systems such as cameras anymore.
The next application of joint design of optics and image processing was to simplify the design of lenses. The complete lens on your mobile phone camera might have seven or eight component lens elements, and a lens on a professional photographer’s camera might contain 15 or more. Multiple lens elements are necessary to correct imperfections or aberrations, such as color blurring or image warping, that are inherent in real optical systems—all to make an optical image that “looks good.” Joint design of optics and digital processing could move some of the burden of correcting aberrations onto digital processing, thereby allowing some of the lens elements to be eliminated without compromising final digital image quality. One can think of the processing algorithms as acting as a form of virtual lens element. This approach has led to lensed systems that are a bit smaller and less expensive for a given quality of final digital image.
Some of us asked: How far can we push these ideas? How much of the imaging burden can be moved from the optics to the computation? How simple can we make the optics and still get a usable digital image? Can we eliminate lenses and curved mirrors altogether? In the past few years, this last goal has been achieved in three primary ways—all of which eschew lenses and the traditional optical images that lenses create. These three methods are based on diffraction, optical phase reconstruction, and compressive sensing. All rely heavily on computation to yield the final, human- interpretable digital image.
Traditional lenses focus light through the process of refraction, in which light bends when passing from one medium (such as air) into another medium in which its speed differs (such as glass or plastic). Refraction explains why a pencil dipped into a glass of water appears bent at the surface: The light from the pencil underwater bends when it passes into the air on its way to your eye; thus you see the underwater portion of the pencil as displaced. Curved mirrors, such as those used in large astronomical telescopes, form an image differently, by exploiting reflection. The reason you look distorted in a fun-house mirror is because of reflections from the undulating mirror. Refraction and reflection can be understood by visualizing light as though it travels in in lines or rays.

Two other physical processes can be used to change the direction of light propagation and to exploit the wave nature of light: diffraction and interference. When two light waves meet, their wave values add. If a peak from one wave always meets a peak from the other wave, the values reinforce, a process called constructive interference, which yields increased light. If a peak always meets a valley, however, the waves cancel each other—destructive interference—yielding no light.
A common way to control light through diffraction is by directing light onto a diffraction grating, often simply called a grating—patterns of microscopic ridges on a surface. Because different wavelengths of light diffract into different directions, colors spread out; for instance, when white light reflects from the teeny ridges on the surface of an audio compact disc or DVD, those surfaces appear to be rainbow-colored. Because of the wavelength dependency of gratings, one cannot design a grating that will simply replace a lens; the optical image from a grating will never look quite as good as one produced by a carefully designed lens. Nevertheless, with proper design of both the diffractive optics (to exploit diffraction) and matched signal processing (tailored to the optics), acceptable digital images can indeed be created.
One class of lensless devices for imaging macroscopic objects relies on miniature gratings consisting of steps in thickness in a transparent material (glass or silicate) that delay one portion of the incident light wave with respect to another portion. The pattern of steps expresses special mathematical properties that uniquely ensure that the pattern of light in the material does not depend much on the wavelength of the light and thus upon the unintended variations in thickness arising during the manufacture of the glass. These gratings are affixed atop a photodetector array—much like the light-sensitive sensor used in a traditional digital camera. The light from the scene diffracts through the grating, yielding a pattern of light on the array that does not appear like a traditional image—it does not “look good” but instead more like a diffuse blob, unintelligible to the human eye. Nevertheless, the blob contains enough visual information (albeit in an unusual distribution) such that the desired image can be reconstructed through a computational process called image convolution.
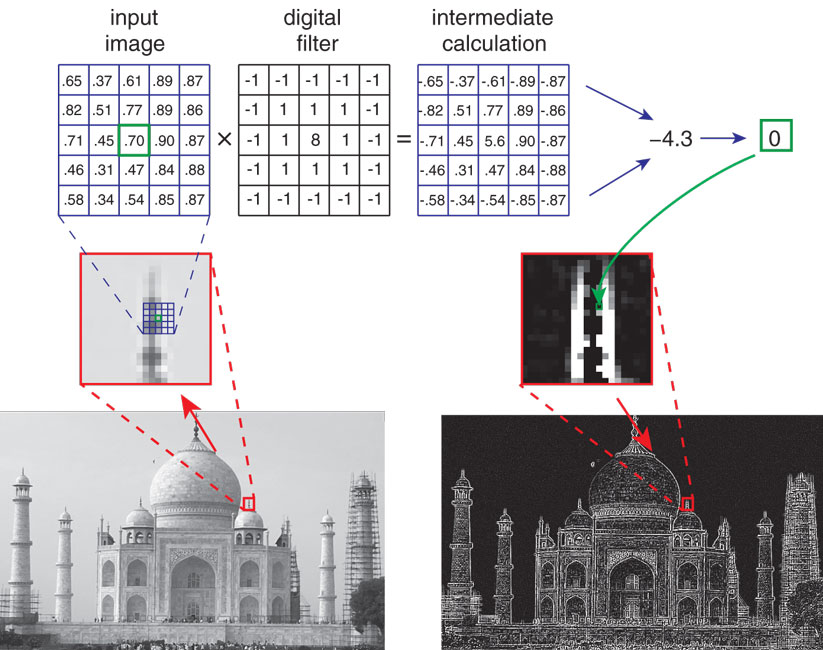
Image courtesy of David G. Stork, Aydogan Ozcan, and Patrick R. Gill
The image reconstruction algorithm is a bit sensitive to visual noise, such as random fluctuations in the number of photons, or electrical noise when converting sensor signals into digital numbers (so-called quantization error), among others. As a result, the final digital image might appear a bit speckled. Although such an image might suffice for a range of simple applications—for instance, counting people in a scene—forming a higher quality image may require that more information be captured from the scene. A straightforward approach is to use several miniature phase gratings, each designed to capture slightly different information from the scene. Each grating leads to a component digital image, and these components can be processed digitally as a group to produce a single, higher-quality image.

Image courtesy of David G. Stork, Aydogan Ozcan, and Patrick R. Gill
This general computational approach can be extended from imaging to sensing—estimating some visual property of a scene, such as the presence or absence of a human face, the direction and speed of the overall motion of the scene (the visual flow), or the number of people in a room. In these cases, one designs the grating to extract the relevant information, and designs the processing algorithm to be tailored to the task in question. For instance, if the sensing task is to read a vertical barcode, one should use a grating that is itself vertical, and signal processing that first thresholds every pixel in the digital image so that lighter pixels are converted to white, and darker pixels are converted to black. Thereafter, the black and white digital image can be read using a barcode-reading algorithm.
The approach to making a lensless microscope differs somewhat from a computational macroimager or camera, but it too relies upon diffraction of light. Unlike the case of an imager for a scene in natural light, such as sunlight or room lamps, in microscopy one can use coherent laser light or monochromatic light from single or multiple sources. In this case, the effects of diffraction and light interference can be controlled or engineered. Moreover, the objects of interest are small, and thus the diffraction is from the samples themselves, rather than from an engineered grating.
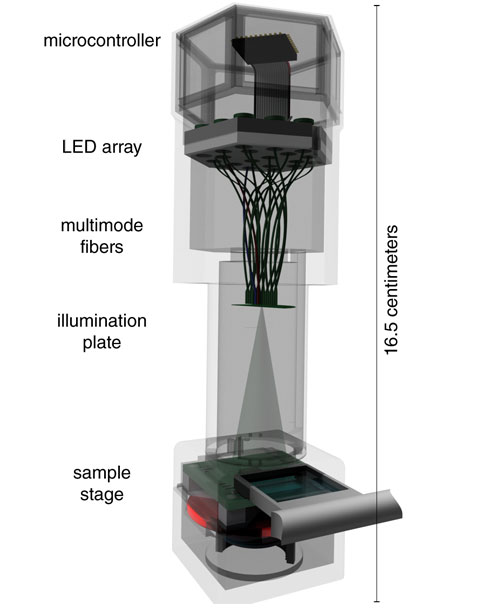
Image courtesy of David G. Stork, Aydogan Ozcan, and Patrick R. Gill
A basic design for a lensless microscope calls for the specimen to be placed atop a photodetector array having a large number of small pixels, for instance a 10-megapixel photodetector array often found in digital cameras. Such a design is also referred to as an “on chip” microscope, because the sample is directly positioned on an imager chip. Light from a laser or spectrally pure colored light-emitting diode (LED) shines through the sample and diffracts around the specimens. These diffracted waves—comprising the object beam—interfere with the illumination that passes straight through the sample—the reference beam—creating a complex interference pattern sensed by the photodetector array in a process called digital in-line holography. This raw optical image vaguely resembles microscopic shadows of the sample, and in some cases can be used to get a rough idea of the number and placement of the target. However, this raw holographic image is rather blurry, mottled, contains “ring artifacts,” and does not closely resemble the morphology of the specimens. It does not “look good.”
The interference pattern is digitally processed through a number of steps, but the central step is a phase recovery algorithm that incorporates knowledge of the physics of optical interference to infer the structure and position of the cells in the specimen. In brief, this algorithm searches for the optical phase information of the sample that is lost in the hologram on the sensor array (which records just the interference pattern, not the phases of the individual light beams themselves). The algorithm iteratively seeks the phase information in the object beam most likely to have produced the detected optical interference pattern. Once this phase information of the object beam is estimated, it is computationally propagated backward (or time-reversed) to infer the images of the object and thereby yield the final digital image.

Images courtesy of David G. Stork, Aydogan Ozcan, and Patrick R. Gill
Much as with the macroimager, one can get higher resolution digital images by capturing multiple optical images, each bearing slightly different information. One simple approach to this end is to shift the illumination source, the sample, or the sensor array slightly between each exposure. The resulting individual images are then digitally integrated to yield a single higher-resolution interference image (which still remains uninterpretable by the human eye) before the phase recovery and time-reversal steps are applied.
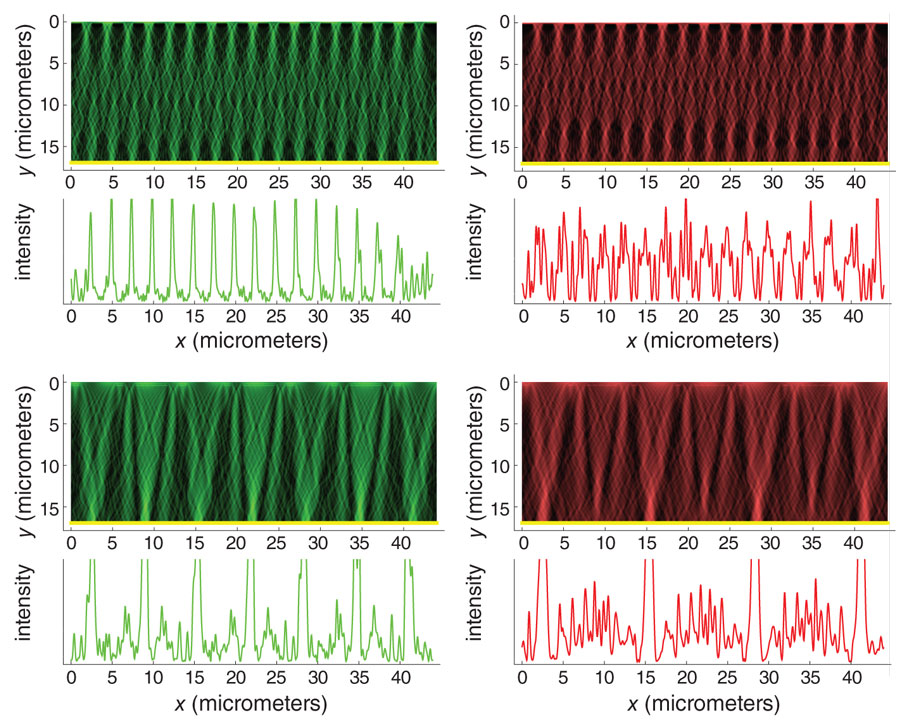
Image courtesy of David G. Stork, Aydogan Ozcan, and Patrick R. Gill
There are several benefits of having such lensless microscopy tools implemented on a chip. First, the area of sample that can be sensed (that is, the equivalent field of view) can be extremely large—as large as the area of the sensor itself, because the sample is placed directly on top of the sensor array. A field of view of 20 square millimeters to 20 square centimeters can be achieved using modern photodetector chips. Second, lensless microscopy can even reveal transparent and clear objects, so long as they affect the phase of light passing through them, as do tiny glass beads and most bacteria in water. (Special lens-based optical microscopes can also reveal such “phase objects,” although over much smaller fields of view and sample volumes.) Third, digital processing of the optical image can distinguish different cell types and track their motion, such as motile sperm cells or blood cells flowing through a small channel, providing data useful in medicine and biology. Fourth, these microscopes are significantly less expensive and more portable than their lens-based counterparts; they can be attached to a mobile phone and used in rural areas of a developing country, and the image data can then be sent anywhere in the world for professionals to analyze remotely.
Image courtesy of David G. Stork, Aydogan Ozcan, and Patrick R. Gill
The third general approach to lensless imaging is based on a recent advance in the mathematics and statistics of signals known as compressive sensing. An optical image on a sensor is just a complicated signal that can be represented as a list of numbers and processed digitally. Just as a complicated sound can be built up from a large number of simpler sounds, each added in a proportion that depends on the sound in question, so too can an image be built up from lots of simpler images. The set of simpler images or signals is called a basis. In sound, the most common basis is the set of pure cosine-wave tones. No matter how complex a sound is—from a car horn to a Beethoven symphony—it can be created by adding together a large number of such basis cosine waves, each with the appropriate intensity and shift in time.
What would be the corresponding basis for images? Two of the most popular and useful image basis sets are two-dimensional cosine waves, and multi-resolution wavelet patterns. These base elements are mathematically elegant and serve as the foundation for existing image compression schemes such as JPEG and JPEG 2000. Rather than store or send every pixel value in a digital image, you merely send or store a digital file describing the amplitudes of the different component basis signals. The “compressed” file is thus much smaller than the image itself. For decades these bases have served the digital-image processing community well, but they have not led to new optical design principles in large part because no optical element easily implements any bases.
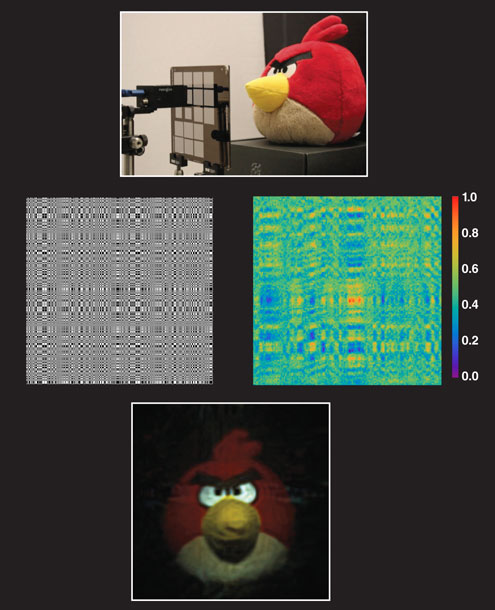
Images courtesy of Ashok Veeraraghavan.
Enter compressive sensing. Theoretical results from statisticians have shown that, as long as the information from the scene is redundant (and the image is thus compressible), one does not need to measure such mathematically elegant bases, but can use measurements from a suitably random one. If such “coded measurements” are available then one can still exploit the idea that the signal can be well represented in the elegant basis elements (such as cosines or wavelets) and recover the image through compressive sensing. Moreover, with this special class of new reconstruction methods, one generally needs far fewer measurements to reconstruct an image than was previously thought.
This theoretical insight expanded the opportunities for new classes of optical designs for cameras based on early advances in X-ray and gamma-ray imaging. Coded apertures (a suitably designed fixed two-dimensional mask pattern of transparent and opaque regions), can potentially provide an elegant means to capture coded measurements from the scene onto a traditional image sensor array. One design, called FlatCam, has been developed by Ashok Veeraraghavan and his colleagues at Rice University, and consists of a simple amplitude mask placed on top of a traditional image sensor array (see figure above). Light from the scene—here, a stuffed toy—passes (and diffracts) through the transparent regions of this amplitude mask and reach the image sensor. Note that there is no lens, and thus no traditional optical image is ever formed. Instead, the sensor records a complex, apparently chaotic pattern of light that contains information both about the scene and about the mask pattern. Because this single image consists of several pixels, each of those pixels provide different coded measurements about the scene. Later, a digital algorithm finds the “simplest” scene that is consistent with all the measurements by exploiting the mathematical and algorithmic methods of compressive sensing.
There are several significant advantages to this lensless imaging approach. The cost of traditional cameras is dominated by lenses and post-fabrication assembly, so eliminating lenses from the design could lead to inexpensive cameras. In addition, the entire camera design, including the mask and the sensor, could potentially be made using traditional semiconductor fabrication processing techniques, providing benefits in terms of scalability and cost. Also, this redesign yields cameras that are thinner than 0.5 mm and weighing less than 0.2 grams, possibly enabling novel applications where today’s bulky designs are an impediment. And although it is inspired by compressive sensing, the FlatCam approach allows all necessary information to be captured from a single snapshot, thereby enabling real-time, video-rate capture of dynamic scene information.
Designers of imaging systems are entering a new era, one in which optical elements, which exploit the physics of light and tangible materials, can be designed along with digital algorithms, which involve the intangible realm of information. Many of the familiar principles and informal rules of thumb that have guided optical designers for centuries are being overthrown, including the need for lenses and curved mirrors or structured digital bases such as cosine functions. We find traditional optical images so familiar and useful that we have been reluctant to consider them instead more abstractly, as information.
Future directions for our macroscale sensors and imagers include the design of application-specific gratings and processing algorithms. For instance, if the task is to detect the presence of a human face, then the grating itself should extract, to the extent possible, only visual information indicative of faces. Another intriguing direction is to place as much of the end-to-end computational burden as possible onto the optics, so as to reduce the digital processing steps and thus reduce the electrical power dissipation. In lensless microscopy, we seek to increase the spatial and temporal resolution, and to design digital microscopes tailored for the diagnosis of specific diseases, particularly those plaguing the developing world.
Lenses and curved mirrors have served us well for centuries, and it’s likely they will never be eliminated from imaging technology. Nevertheless, the recent paradigm of computational imaging is showing new ways forward, leading to devices (and paired computation) that use these familiar devices in new ways, or eschew them altogether.
Click "American Scientist" to access home page

American Scientist Comments and Discussion
To discuss our articles or comment on them, please share them and tag American Scientist on social media platforms. Here are links to our profiles on Twitter, Facebook, and LinkedIn.
If we re-share your post, we will moderate comments/discussion following our comments policy.